- Solan Sync
- Posts
- OpenAI Unveils GPT-4.1: A Game-Changing Leap in AI Performance and Contextual Memory
OpenAI Unveils GPT-4.1: A Game-Changing Leap in AI Performance and Contextual Memory
OpenAI's GPT-4.1 just launched with game-changing upgrades - 1 million token context, top-tier coding accuracy, and advanced image and instruction understanding. Discover how it outperforms GPT-4o.
Solan Sync
April 15, 2025
🚀 GPT-4.1 Is Here: OpenAI Unveils Its Most Powerful AI Model Yet
In a significant leap forward for generative AI, OpenAI has officially released GPT‑4.1, a new state-of-the-art language model that promises faster performance, better coding capabilities, and context handling that blows its predecessors out of the water. Unveiled alongside lightweight variants like GPT-4.1 Mini and Nano, this upgrade signals a major transformation in how developers, researchers, and enterprises will interact with large language models in real time.
The most headline-grabbing feature? GPT-4.1 can process up to 1 million context tokens, a staggering upgrade that allows it to ingest and reason over vast amounts of information — entire codebases, books, or complex legal documents — without losing coherence. And that’s just the beginning.
Let’s break down what GPT-4.1 brings to the table and why it’s already being hailed as a game-changer.
GPT-4.1 vs GPT-4o and GPT-4o Mini: A Major Performance Leap

More Than Just a Minor Upgrade
While GPT-4o and GPT-4o Mini offered improvements over GPT-4 in terms of speed and cost, GPT‑4.1 significantly outperforms both models across nearly every metric, including accuracy, instruction-following, and multi-turn conversation handling.
OpenAI released three versions to suit different use cases:
GPT-4.1: Full-featured and high-performance
GPT-4.1 Mini: Lightweight for quick tasks with reduced latency
GPT-4.1 Nano: Designed for on-device inferencing and low-resource environments
This tiered approach lets developers tailor AI performance to their exact needs — without compromising on core model capabilities.
Coding Superpowers: GPT-4.1 Achieves 55% Accuracy in Complex Programming Tasks

One of the standout improvements in GPT-4.1 is its massive boost in programming accuracy. Benchmark tests show:
GPT-4.1 achieves 55% accuracy on complex coding tasks, compared to 33% with GPT-4o
It produces fewer bugs, more readable logic, and cleaner code structure
It’s now considered twice as good at code diffs — the ability to detect, explain, and fix differences between code versions
What This Means for Developers
With GPT-4.1, developers can:
Refactor large codebases with AI assistance
Handle language translations (e.g., Python to TypeScript) with greater reliability
Generate unit tests and documentation more effectively
Use the model as a real-time code review assistant, reducing reliance on human QA
This is especially beneficial for teams managing legacy software systems or large-scale frameworks like React, Angular, or Django.
1 Million Token Context: The End of Context Limitations?
A Quantum Leap in Memory Capacity
Perhaps the most revolutionary advancement of GPT‑4.1 is its 1 million token context window. To put that into perspective:
1 million tokens equals roughly 750,000–800,000 words
That’s the size of 8+ full React codebases, a dozen technical manuals, or hundreds of pages of legal contracts
Real-World Use Cases
This expanded context capability means GPT-4.1 can now:
Process entire multi-repository codebases at once
Conduct in-depth legal analysis across full-length documents
Analyze large datasets with embedded narratives (e.g., CSVs, JSON, PDFs)
Maintain conversation continuity over long chat histories — critical for customer support or tutoring use cases
It effectively eliminates the need to chunk or summarize input manually — a time-consuming step that often leads to loss of nuance.
🧠 GPT-4.1 Handles Deep Reasoning and Near-Duplicate Answers with Ease
Smarter Than Ever at Reading Between the Lines
One of the most underrated but powerful upgrades in GPT‑4.1 is its ability to extract multiple correct answers hidden within long, complex texts, especially when those answers appear similar or are subtly worded.
For use cases in:
Compliance (e.g., identifying legal clauses in contracts)
Academic research (e.g., extracting hypotheses or evidence across journals)
Enterprise search (e.g., querying knowledge bases with fuzzy or ambiguous queries)
GPT-4.1 showcases an elevated understanding of nuance, context shifts, and paragraph-level logic chains. Unlike earlier versions that might miss overlapping or closely worded information, GPT-4.1 reads like a human subject-matter expert — identifying not just “what” but also “why” and “how.”
🛠️ Code Editing Mastery: GPT‑4.1 Is Twice as Good at Diffs

Editing existing code — especially understanding how a new snippet differs from the old one — is historically hard for AI. But GPT‑4.1 tackles this with twice the accuracy of GPT‑4o and even outperforms GPT‑4.5 in various diff-related benchmarks.
What This Means for Real-World Teams
Automatically summarizes code changes across PRs
Flags potential regressions or security vulnerabilities in edits
Understands intent behind a change, not just its syntax
Works seamlessly with version control systems like Git
This allows engineering teams to accelerate CI/CD pipelines, reduce bugs before deployment, and ensure code reviews happen in real time — especially useful in large-scale enterprise environments or rapid product iteration cycles.
📋 GPT‑4.1 Follows Complex and Precise Instructions Exceptionally Well
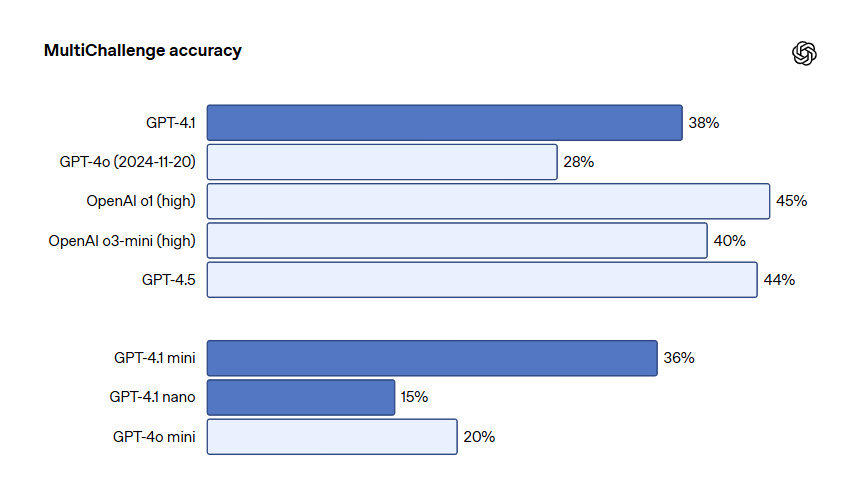
Instruction tuning — the ability for AI to follow structured prompts or complex natural language directions — is another standout win.
Benchmark: 87% accuracy on IFEval, compared to 81% with GPT-4o
Real-Life Implications
GPT-4.1 can now:
Follow multi-step instructions with fewer hallucinations
Obey fine-grained constraints, such as formatting, tone, or structure
Support enterprise workflows with reliability at scale (e.g., auto-generating reports or summaries in legal, finance, and healthcare)
Reduce the need for prompt engineering or “prompt stacking” tricks
If GPT‑4o was great at doing what you asked, GPT‑4.1 is better at doing exactly what you meant — even when your instructions are subtle or imperfect.
💬 More Accurate Memory in Multi-Turn Conversations

Context retention in long chats — a common challenge for customer support bots, tutoring platforms, and AI assistants — gets a boost in GPT‑4.1.
Key Enhancement
GPT-4.1 shows a 10% increase in accuracy across multi-turn conversations compared to GPT‑4o.
This improvement means:
Fewer “reset” moments in long conversations
Better understanding of prior intent and questions
Smoother dialogue experiences for chatbots, AI companions, or enterprise virtual agents
In high-context fields like healthcare diagnostics, legal advice, or technical support, this leads to more natural, less repetitive interactions.
🖼️ Visual Understanding: Images, Charts, and Videos Decoded More Intelligently
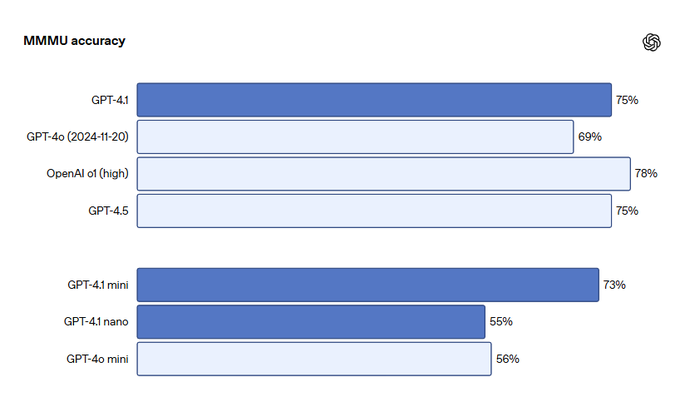
GPT‑4.1 also levels up its multimodal capabilities — especially in processing visual input. Compared to GPT‑4o, it shows:
Better accuracy in reading graphs, charts, and spreadsheets
Deeper understanding of diagrams, infographics, and slide decks
Improved reasoning over image + text combos (e.g., math problems, dashboards)
Emerging capabilities in video comprehension (currently experimental)
This opens doors for:
Data journalists and analysts to auto-summarize complex visual data
Educators to convert visual teaching materials into lessons or quizzes
Accessibility tech that can describe or interpret images for the visually impaired
While image analysis isn’t new, GPT‑4.1 does it with higher semantic accuracy and less guesswork.
⚡ Faster, Cheaper, Smarter: A Win Across the Board

OpenAI isn’t just delivering power — it’s making GPT-4.1 more affordable and efficient:
Faster inference times mean lower latency for real-time apps
Reduced compute cost per token improves affordability at scale
Optimized repetition handling means less wasted tokens and better compression of prompt chains
This positions GPT-4.1 as the default foundation model for developers and enterprises looking for production-ready generative AI tools.
🧾 Final Thoughts: Is GPT‑4.1 the New Standard for Enterprise AI?
With improved instruction-following, deeper reasoning, powerful memory, code editing capabilities, and massive context windows, GPT-4.1 isn’t just an upgrade — it’s a foundation shift. Whether you’re building an AI assistant, refactoring software, or automating enterprise workflows, GPT‑4.1 is a force multiplier.
OpenAI has effectively created a new baseline for generative AI. From chat to code to charts, GPT‑4.1 is leaner, faster, more scalable — and significantly more intelligent.
Reply